vlad descriptors
an improvement on BagOfWords descriptors;instead of increasing histogram bins for matching features / codewords:

we calculate the residual (the difference, 1st order moment) between the (SIFT or SURF) descriptor and it's closest dictionary entry:
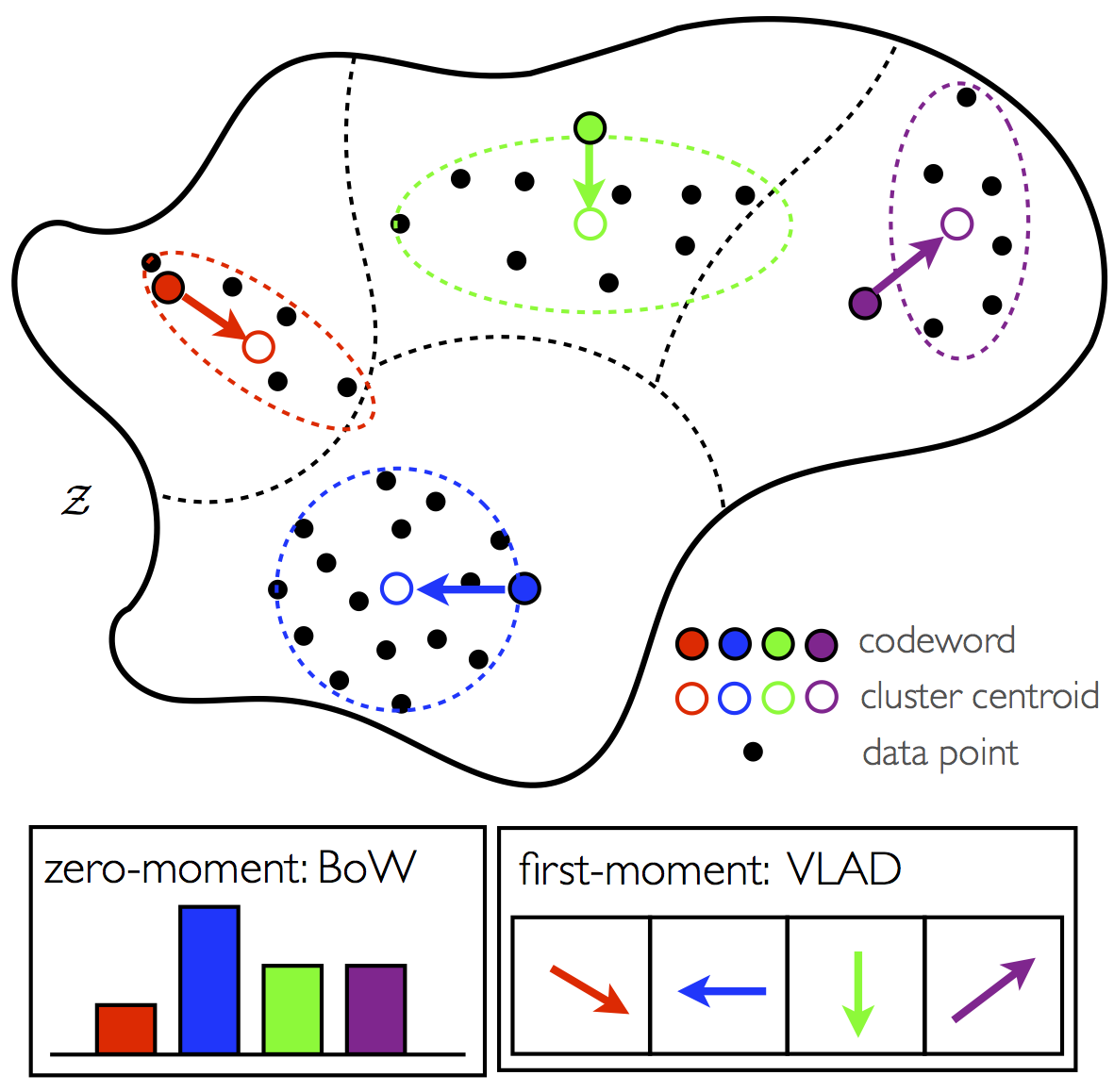
and add them up (per dictionary entry). after extensive normalization, we get a feature in the same size of the dictionary.
the upside of it is this:
only very coarse (kmeans) clustering is needed for this, like K=64 will do.
(while you need a significantly large K for BoW (i've seen like 20k used), to get hold of the really relevant cluster centers)